在多模态学习的浪潮下,大型模型(MLLMs)在“看图说话”和“听声答题”等任务上表现出色。然而,令人惊讶的是,它们在“数一数”这种看似简单的小事上却常常出错。
例如,“视频中跳水前到底喊了几声?”、“鸡圈里到底有几只鸡?”或者“房间里到底有几种颜色的花盆?”这些看似简单的问题,却暴露出多模态大模型在细粒度感知、时空定位以及推理链构建等方面的重大短板。
计数任务:多模态理解的试金石,却也是软肋
近年来,多模态大模型(MLLMs)快速崛起,已在图像描述、视频问答、时空定位等任务中取得惊艳成绩。然而,这些模型在计数任务中的表现,却远远落后于其他任务。
计数问题看似简单,实则蕴含着模型推理能力的集中考验:
| 问题 | 背后考验的能力 |
| 鸡圈里有几只鸡? | 物体识别 + 多实例去重 + 时空追踪 |
| 跳水前喊了几声? | 音频识别 + 时间轴事件定位 |
| 卧室里有几种颜色的花盆? | 属性分类 + 群组聚合 + 视觉对比 |
这些任务不仅仅是“识别”,更是细粒度对齐、模态融合和逻辑推理的集合体,要求模型具备以下能力:
明确目标:知道“数的是谁”
对齐模态:能从视觉/音频中捕捉到相关线索
理解时序:区分出现顺序与重复实例
控制输出:准确输出数字,且符合格式要求
当前的多模态模型缺乏专门的数据和训练策略,在这些方面几乎处于“裸奔”状态。最核心的问题是现有评估体系不足,甚至无法判断模型究竟是“真的会数”,还是“猜了个接近的数”。
CG-AV-Counting:打破“蒙对也算对”的计数评估方式

为了解决“评估不准确”的问题,研究人员构建了 CG-AV-Counting,这是目前最复杂、最可解释的多模态计数评估基准。
数据特点:
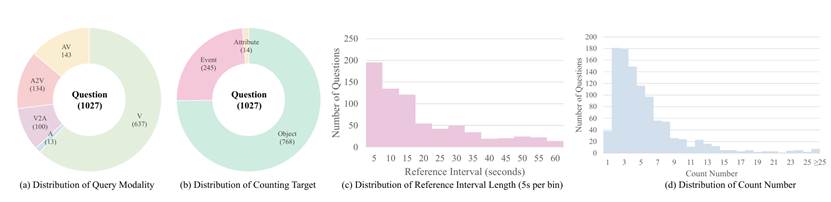
- 497 条视频,全部为真实世界场景,每条超过 10 分钟
- 1,027 个计数问题,覆盖视觉、听觉、视听混合、交叉查询等多模态形式
- 5,845 条人工标注的线索,首次提供细粒度计数证据(例如每只鸡的位置、每声喊叫的时间区间)
- 3类计数对象,涵盖了事件、物体、属性的计数对象,全面评估模型的时空定位与推理能力
双重评估方法:
- 黑盒评估:只看最终答案准不准
- 白盒评估:看模型能不能准确指出每个事件/物体/属性的“位置”,从而解释为什么是这个数。为此,我们提出了一个新的综合指标 WCS,用来衡量模型“数得对 + 数得明白”的能力。
评测结果:
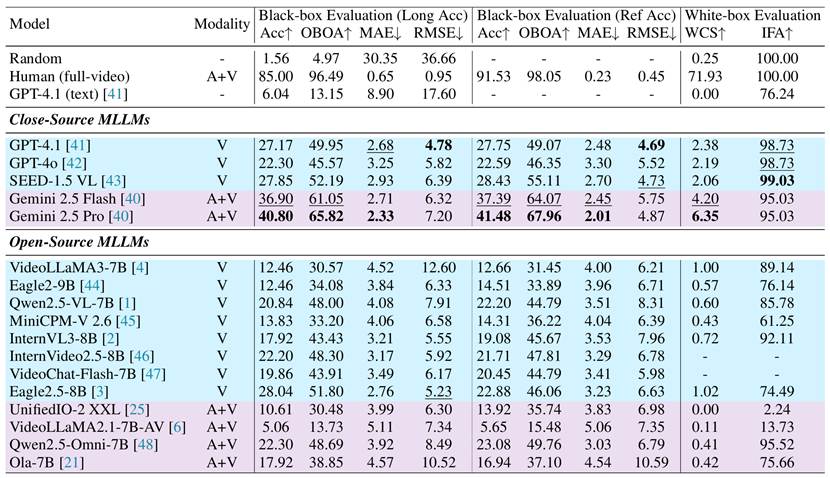
CG-AV-Counting 的评测结果表明,当前主流的多模态大模型在长视频计数任务上整体表现不佳,尤其在需要明确推理过程的白盒评估中普遍得分严重。尽管闭源模型(如 Gemini 2.5 Pro)表现优于开源模型,但即便最强的模型与人类水平仍有显著差距。同时,多数音视频模型未能充分利用音频模态,反映出当前MLLMs在时序对齐、线索定位和格式控制等方面仍存在明显短板,凸显了精细化监督与结构化评估的重要性。
AV-Reasoner:课程学习式GRPO强化微调,让模型从相关任务中学会计数

为了突破当前多模态大模型在计数能力上的瓶颈,研究人员设计并提出了 AV-Reasoner——一个基于课程学习式GRPO强化学习的基线模型。与常规监督微调方法不同,AV-Reasoner不依赖大规模计数标注数据,而是通过构建可迁移能力路径、设计逐步进阶的训练流程,以及引入结构化奖励机制,系统性地构建模型的计数能力和推理能力。
该方法体系由以下三个核心组成部分构成:
1. SFT 冷启动:学会结构化输出,为强化微调打基础
研究人员选择 Ola -7B 作为基础模型,首先在音视频问答(AVQA)、音视频事件定位(AVTG)和视觉/音频参考定位(ARIG)等任务上进行监督微调,使模型能够结构化地进行输出,同时提高模型的基础能力,为强化微调打下基础。
2. 课程式强化学习:循序渐进地教模型“推理计数”
在具备一定多模态能力后,AV-Reasoner并未立即进行统一强化训练,而是采用了课程式的学习路径。训练任务被划分为三个难度递增的阶段:QA、Grounding和计数。这种“先会看,再会找,最后会数”的学习路径,明显优于直接对复杂任务进行强化训练的方式,也更符合人类的学习规律。
在课程学习中,模型常面临新任务学好、老任务遗忘的关键问题。为克服“灾难性遗忘”, AV-Reasoner使用了阶段复习机制。在每一个强化学习阶段中,前一阶段20%的样本会被随机混入当前训练集,从而使模型持续“温习”之前的任务能力,保持跨阶段的一致性与稳定性。
3. 全任务强化学习:全面回顾,强化整合能力
在完成课程式多阶段强化训练后,尽管模型已掌握各类子任务的核心能力,但由于每一阶段的目标不同,模型可能仍缺乏在混合任务条件下的鲁棒性和应变能力。为此,研究人员设计了训练流程的第三阶段:全任务强化学习,作为一次“强化总复习”,让模型在统一条件下优化多任务能力,提升系统整合与泛化能力。
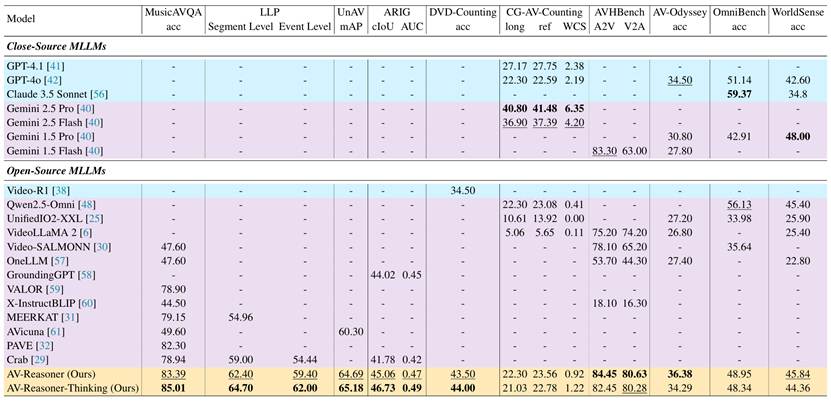

实验结果表明,面对复杂的视频计数任务,AV-Reasoner 相较于基础模型,性能提升显著。在多项视听相关基准测试中,它展现出了惊人的泛化能力和卓越性能,达到了或超越了当前的SOTA水平。AV-Reasoner 的成功证明了通过强化学习和精心设计的训练范式,能够有效解锁多模态大模型在细粒度任务上的潜力。它不仅为视频计数提供了突破性的解决方案,也为未来构建更强大、更智能的AV理解系统指明了方向。
然而,实验也发现,强制模型在语言空间进行推理并非总是灵丹妙药,甚至可能带来意想不到的“副作用”。当模型在域外基准测试中被强制要求在语言空间进行推理时,性能提升并不明显。如果模型在多模态理解上本身就存在短板,那么即使强制其进行“思考”,它也可能只是在语言层面“凑合”出答案,而非真正地从多模态信息中提取和推理出正确的结果。这种“假”推理反而会掩盖模型在底层多模态对齐和理解上的真正问题。
结论
CG-AV-Counting 作为拥有长视频、多模态问题和丰富线索标注的基准,彻底解决了现有计数数据集的局限性。它不仅是衡量模型“数数”能力的试金石,更是推动未来研究的重要工具。而 AV-Reasoner 凭借强化学习和课程学习策略,在CG-AV-Counting等多个计数基准上实现了显著的性能提升,同时在其他AV相关任务中也展现了超越SOTA的强大实力。这证明了强化微调方法的巨大潜力。然而,研究也带来了深刻的洞察:强制模型在语言空间进行推理,尤其是在域外场景下,效果可能适得其反。这警示着,真正的多模态理解需要视听信息间的深度融合与原生推理,而非简单的语言层面“强制思考”。
参考论文:AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs
论文地址:https://arxiv.org/abs/2506.05328
Hugging Face 页面:https://huggingface.co/papers/2506.05328